Introduction à HTTP pour le développement frontend
Auteur(s) de l'article
Dans ce vaste monde du web, chaque interaction, que ce soit l'ouverture d'une page web, la soumission d'un formulaire ou le visionnage d'une vidéo, tout repose sur un protocole appelé HTTP (HyperText Transfer Protocol). Dans cet article je vais partager les bases qui selon moi sont importantes à connaître pour une ou un développeur frontend.
Le rôle de HTTP est d'agir comme le messager entre le client (le navigateur de l'utilisateur) et le serveur.
Lorsque vous saisissez une URL ou cliquez simplement sur un lien, vous envoyez une requête HTTP. Le serveur reconnaît (ou non) la demande et renvoie une réponse avec le contenu que vous avez demandé.
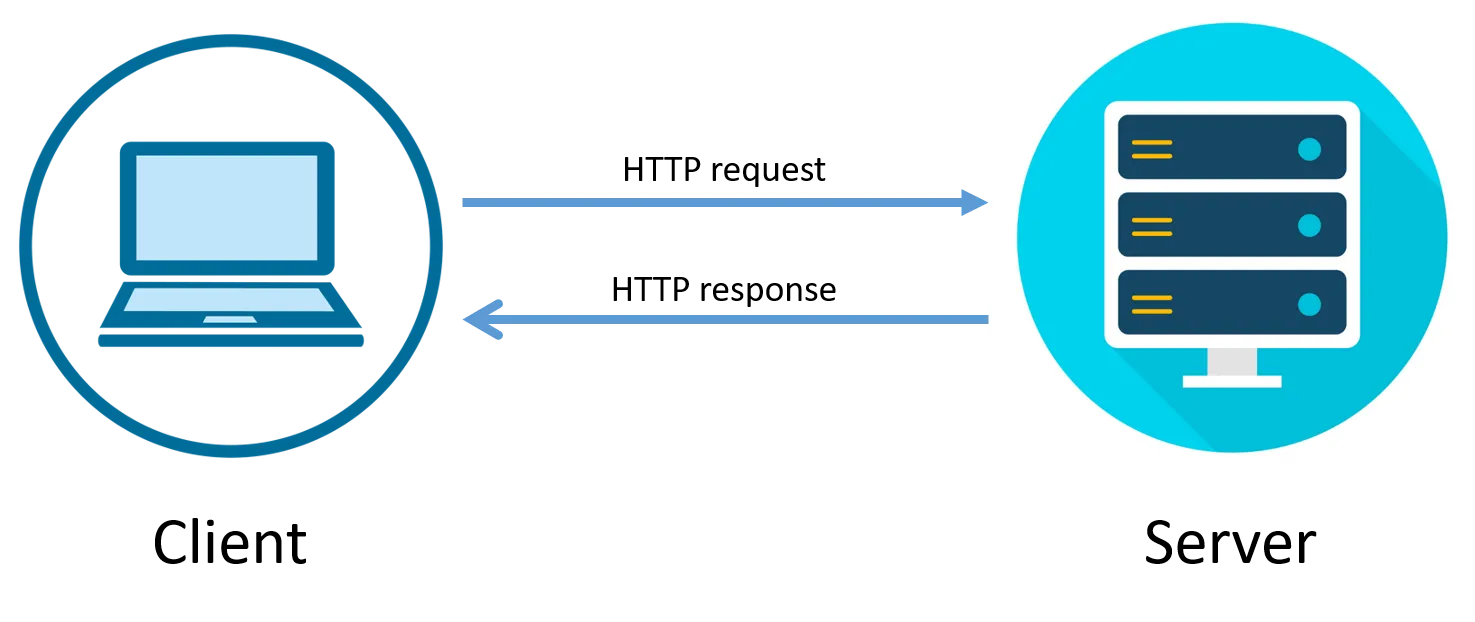
On pourrait faire une analogie avec par exemple un restaurant. Vous (le navigateur / client) passez votre commande (requete HTTP). La commande est emmenée à la cuisine (le serveur web), la commande est ensuite préparée et vous est ramenée (réponse HTTP).
Pourquoi est-il important pour un développeur frontend de comprendre le protocole HTTP ?
En tant que développeur frontend, vous devez fréquemment interagir avec les services provenant du backend. Le fait de connaître le protocole HTTP va vous permettre de communiquer efficacement avec ces services afin de traiter des données de la manière la plus optimale pour votre site.
Vous avez probablement déjà entendu le terme CORS, ou bien vous vous êtes déjà pris une erreur 404. C’est dans ce genre de cas ou des connaissances du protocole HTTP vous aides a comprendre ce qui vous arrive.
Ça pourra aussi éveiller votre curiosité et vous permettre de développer des compétences pour utiliser des techniques comme le lazy loading, le caching, etc. Tout ça pour offrir de meilleures performances à vos utilisateurs.
Au-delà de GET et POST
Les verbes HTTP, souvent appelés méthodes HTTP, définissent l'action que nous avons l'intention d'effectuer sur une ressource donnée.
Ces méthodes offrent bien plus que la simple capacité de récupérer des pages web avec
GET ou de soumettre des données avec POST.Voici des méthodes qui pourraient vous être utiles (continuons avec des analogies culinaires) :
GET
- Analogie : Prendre le lait du frigo.
- Cas concret : Récupérer des données. Lorsque vous chargez une page web, votre navigateur utilise une requête
GETpour récupérer le contenu.
POST
- Analogie : Ajouter une nouvelle bouteille de soda dans votre frigo.
- Cas concret : Soumettre des données. Lorsque vous remplissez un formulaire d'inscription sur un site web, les données que vous saisissez sont envoyées au serveur à l'aide d'une requête
POST.
PUT
- Analogie : Remplacer votre mayonnaise périmée par un nouveau tube tout frais.
- Cas concret : Mettre à jour des données existantes ou les créer si elles n'existent pas. Si un utilisateur souhaite mettre à jour les informations de son profil, une application frontend pourrait utiliser une requête
PUT.
PATCH
- Analogie : Ajouter une tranche supplémentaire de fromage dans votre sandwich.
- Cas concret : Mettre à jour partiellement une ressource. Par exemple, si un utilisateur souhaite changer uniquement son adresse e-mail sur un profil,
PATCHle permet sans affecter les autres données.
DELETE
- Analogie : Composter votre salade toute fanée.
- Cas concret : Supprimer une ressource. Si un utilisateur décide de supprimer son compte, une requête
DELETEserait initiée.
Vous pouvez trouver la liste complète un peut partout en ligne, par exemple sur la doc de mozilla.
ㅤ
Utiliser uniquement
GET et POST peut entraîner des transferts de données inutiles, menant à des applications moins rapides. En revanche, l'utilisation appropriée de verbes tels que PATCH peut optimiser le transfert de données, économisant ainsi du temps et de la bande passante, ce qui est un vrai point positif pour une optique durable du développement.418 je suis une théière

Il est bon de savoir ce qu'est un
Status Code, ou en tout cas ce que représente les différentes catégories de ces statuts. Cela facilitera le débuging et pourra par conséquent vous éviter des migraines aiguës.Les statuts HTTP sont regroupés en cinq catégories représentées par le premier chiffre du code. Chaque catégorie indique le résultat général de la demande. Si vous aimez les chats, n’hésitez pas à visiter https://http.cat/ pour des exemples bien sympas.
1xx(Informatif) : Ces codes indiquent généralement une réponse provisoire. La réponse finale réelle suivra la réponse informative.2xx(Réussite) : Cette catégorie indique que la demande du client a été reçue, comprise et acceptée avec succès.3xx(Redirection) : Ces codes indiquent qu'une action supplémentaire est nécessaire pour compléter la demande, souvent sous la forme d'une redirection.4xx(Erreurs du client) : Ces codes indiquent que le client semble avoir commis une erreur. Ils sont utilisés lorsque la demande contient par exemple une syntaxe incorrecte ou ne peut pas être satisfaite.5xx(Erreurs du serveur) : Ces codes indiquent que le serveur n'a pas pu satisfaire une demande valide. Le serveur lui-même est conscient qu'il a une erreur ou est incapable d'effectuer la demande.
Les headers
Ça sonne à votre porte, c'est le facteur qui vient vous déposer votre colis commandé la veille chez [insérez votre e-commerce favori commençant par la lettre G].
Avant même d’ouvrir la boîte, l'étiquette collée sur le carton vous fournit des informations précieuses : l'expéditeur, la destination, potentiellement des instructions spéciales, la valeur marchande, etc.
De la même manière, les headers (en-têtes) HTTP fournissent des informations cruciales sur la demande ou la réponse, indiquant comment elle doit être traitée, quel est son contenu, comment elle doit être mise en cache, qui a les autorisations.
Voici une liste non exhaustive de headers qui je pense sont important à connaître :
Accept
Spécifie les types de médias qu'il est possible de traiter. Les serveurs peuvent ainsi adapter leurs réponses en fonction des capacités du client. Par exemple, un en-tête
Accept peut indiquer que le client accepte les réponses au format JSON (application/json) ou XML (application/xml).Accept: application/jsonUser-Agent
Identifie le navigateur, le système d'exploitation et d'autres caractéristiques du navigateur. Cela permet au serveur de fournir une réponse optimisée en fonction des capacités du client. Les développeurs frontend peuvent parfois utiliser cet en-tête pour effectuer des ajustements spécifiques à un navigateur / OS.
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36Authorization (avec Bearer)
Ce header est crucial pour les requêtes sécurisées. Lorsqu'un utilisateur est authentifié, le serveur attend généralement un token d'accès. Le schéma le plus courant est le schéma "Bearer", utilisé avec les token JWT.
Authorization: Bearer eyJhbGciOiJ-IUzI1NiIhssInR5cCI6IkpX-VCJ9.eyJzddWIiOqiIxMjM-0NTY3ODkwIdiwibmg-FtZSI6Ikpv-aG4gRG9lIiwi-aWF0IjoxNTsdfE2MjM5M-DIyfQ.SflKxwRJSMeKK-F2QT4fwpMeJf36POk-6ymjJV-adQssw5cContent-Type
Indique le type de média du
body de la requête ou de la réponse. Pour les requêtes, cela informe le serveur sur le format des données envoyées, tandis que pour les réponses, cela indique au client comment interpréter le contenu.Content-Type: application/jsonCookie
Ce header contient les cookies qui doivent être inclus dans la requête. Les cookies servent par exemple à maintenir l'état de la session entre le client et le serveur.
Cookie: sessionId=123456; userId=9876Cache-Control
Spécifie les directives de mise en cache dans les requêtes et les réponses. Les développeurs frontend peuvent utiliser cet en-tête pour contrôler le comportement du cache du navigateur.
Cache-Control: no-cache, no-store, must-revalidateㅤ
En comprenant ces quelques headers fréquemment utilisés, les développeurs frontend peuvent améliorer la gestion des requêtes, la sécurité et l'efficacité globale du site web.
Payloads
Qu'est-ce qu'un payload ?
Dans le contexte de HTTP, un payload fait référence aux données transmises dans une requête ou une réponse. Ces données peuvent prendre diverses formes, telles que du texte, du JSON, du XML, voire même des données binaires. Etant donné que ça influe directement sur les données que vos applications envoient et reçoivent, je pense qu’il est important d’en parler dans cet article.
Types de Payloads
Voici quelques exemples classiques de type de contenu utilisé par nous autres frontends:
Text-Based Payloads (basés sur du texte) :
HTML: Le plus courant sur le web, le HTML contient la structure et le contenu d'une page.JSON: largement utilisé pour des données, le JSON est un format léger, facilement lisible et que les développeurs frontend manipulent souvent lors de l’intérraction avec des API.
Binary Payloads (basés sur du binaires) :
Images: Les données d'image, telles que les fichiers JPEG ou PNG, sont souvent transmises en tant que charges binaires dans les requêtes et réponses HTTP.Fichiers: Lorsque les utilisateurs téléchargent des fichiers, la charge utile binaire est utilisée pour transmettre les données du fichier.
Structured Payloads :
XML(eXtensible Markup Language) : Bien moins courant que le JSON, XML est un autre format pour structurer les données de manière lisible par l'homme et compréhensible par la machine.

Prenons l’exemple d’un site de e-commerce
Vous avez comme objectif d'implémenter une fonctionnalité qui permet aux utilisateur·ices d'ajouter des produits à leur panier sans devoir actualiser l'ensemble de la page.
Mises à jour asynchrones du panier :
Sans une compréhension des payloads, le développeur frontend pourrait avoir du mal à communiquer efficacement avec le backend lorsqu'un utilisateur ajoute un article à son panier. Ici, le payload contiendrait les informations sur le produit (ID, nom, quantité, etc.) qui doivent être envoyées au serveur.
Mises à jour dynamiques de l'interface utilisateur :
Une fois que le serveur traite le payload et met à jour le statut du panier, le payload de réponse (par exemple au format JSON) devient important. Il faut l’interpréter pour mettre à jour dynamiquement l'interface utilisateur. Grâce à ça, son panier mit à jour sans devoir recharger la page.
Gestion des erreurs :
Si, pour une raison quelconque, le serveur rencontre un problème, le payload d'erreur devient essentiel. Les devs frontend peuvent utiliser cette réponse pour afficher un message d'erreur utile à l'utilisateur.