Un million d’éléments sur une carte interactive, mode d’emploi.
Auteur(s) de l'article
Récemment, l’un de nos clients, une société immobilière, nous a lancé un défi. Ils souhaitaient une carte interactive présentant l’ensemble de leurs propriétés à travers le monde. Le hic ? Ils possèdent plus d’un million de propriétés. Et c’est ainsi que notre aventure a commencé.
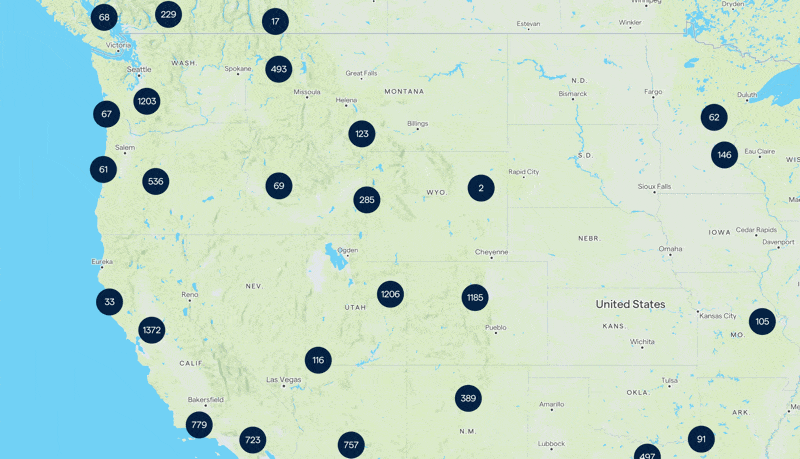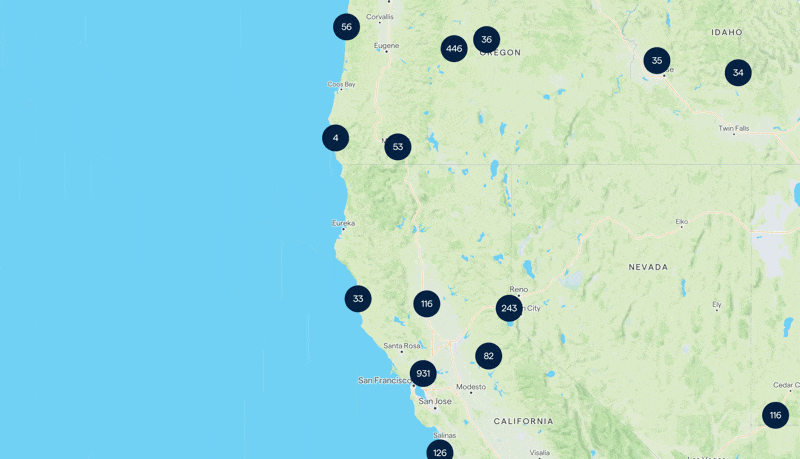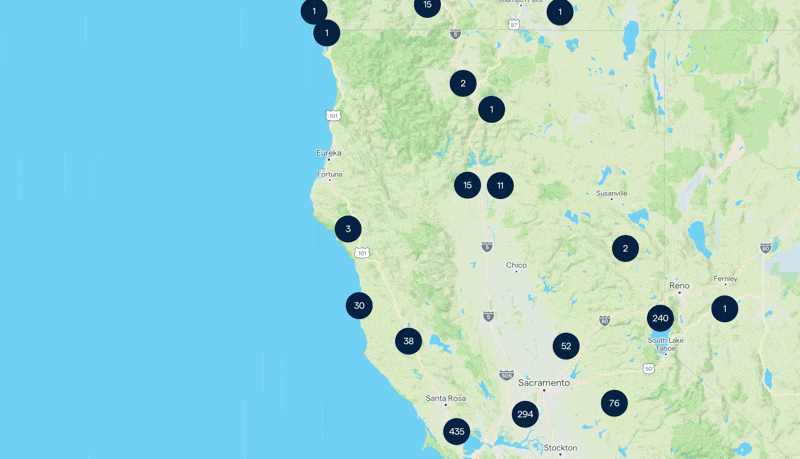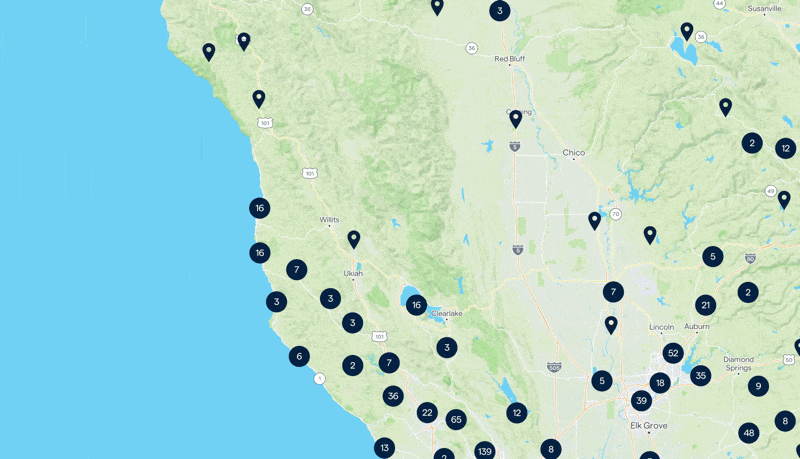
Le résultat de notre carte. Continuez à lire pour découvrir comment nous avons réalisé cela 🥸
À première vue, cela semblait simple. Le véritable défi n’était pas seulement d’afficher des millions de propriétés, mais de le faire de manière rapide et efficace. Une carte qui charge les marqueurs lentement ou qui plante sous le poids des données serait un désastre.
Le scope
Les exigences initiales sont assez simples :
- Afficher des millions de propriétés à travers le monde.
- Montrer des clusters de propriétés lorsque beaucoup se trouvent à proximité, en s’ajustant dynamiquement au fur et à mesure que les utilisateurs zooment ou dézooment.
- La carte doit être extrêmement rapide, quel que soit l’emplacement ou le nombre de propriétés visibles à l’écran.
Je sentais que ce ne serait pas simplement une question de récupérer des données depuis notre Elasticsearch et de les afficher sur une carte.
Imaginez essayer d’afficher chaque propriété comme un marqueur. Le résultat serait une mer de points indéchiffrable, submergeant à la fois la carte et l’utilisateur.

Même avec un clustering côté client, le véritable défi serait la taille de nos données. Imaginez simplement le poids d’une requête API contenant des millions de marqueurs — ce serait un cauchemar pour le transfert de données et le pire ennemi de votre forfait mobile.
Nous devions trouver une solution qui équilibre performance, évolutivité et fonctionnalité.
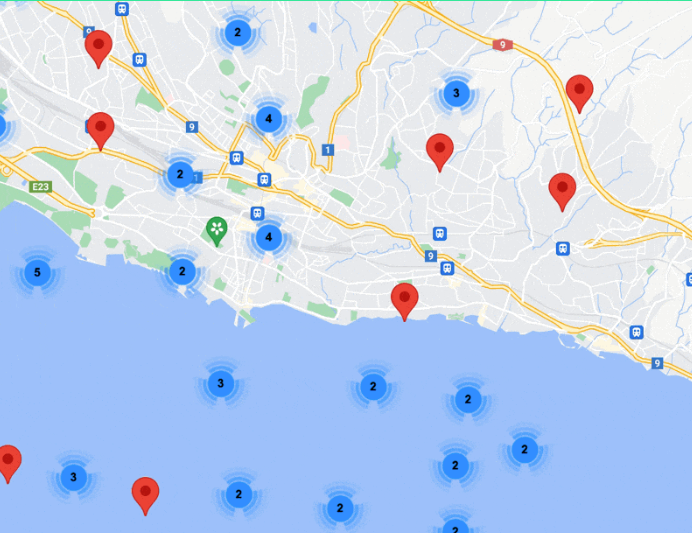
Tout ce dont la plupart des projets auront besoin : le clustering côté client 📍
Brainstorming
Nous avions besoin d’une solution qui équilibre performance, évolutivité et fonctionnalités. Nous avons donc commencé par décomposer le problème.
Filtrage par Bounding Box
Pour réduire le nombre d’éléments demandés depuis notre index, nous avons décidé d’imposer à l’application frontend de fournir une boîte englobante. Cette boîte englobante représenterait la portion visible de la carte sur l’écran de l’utilisateur, en filtrant toutes les propriétés en dehors de cette zone.
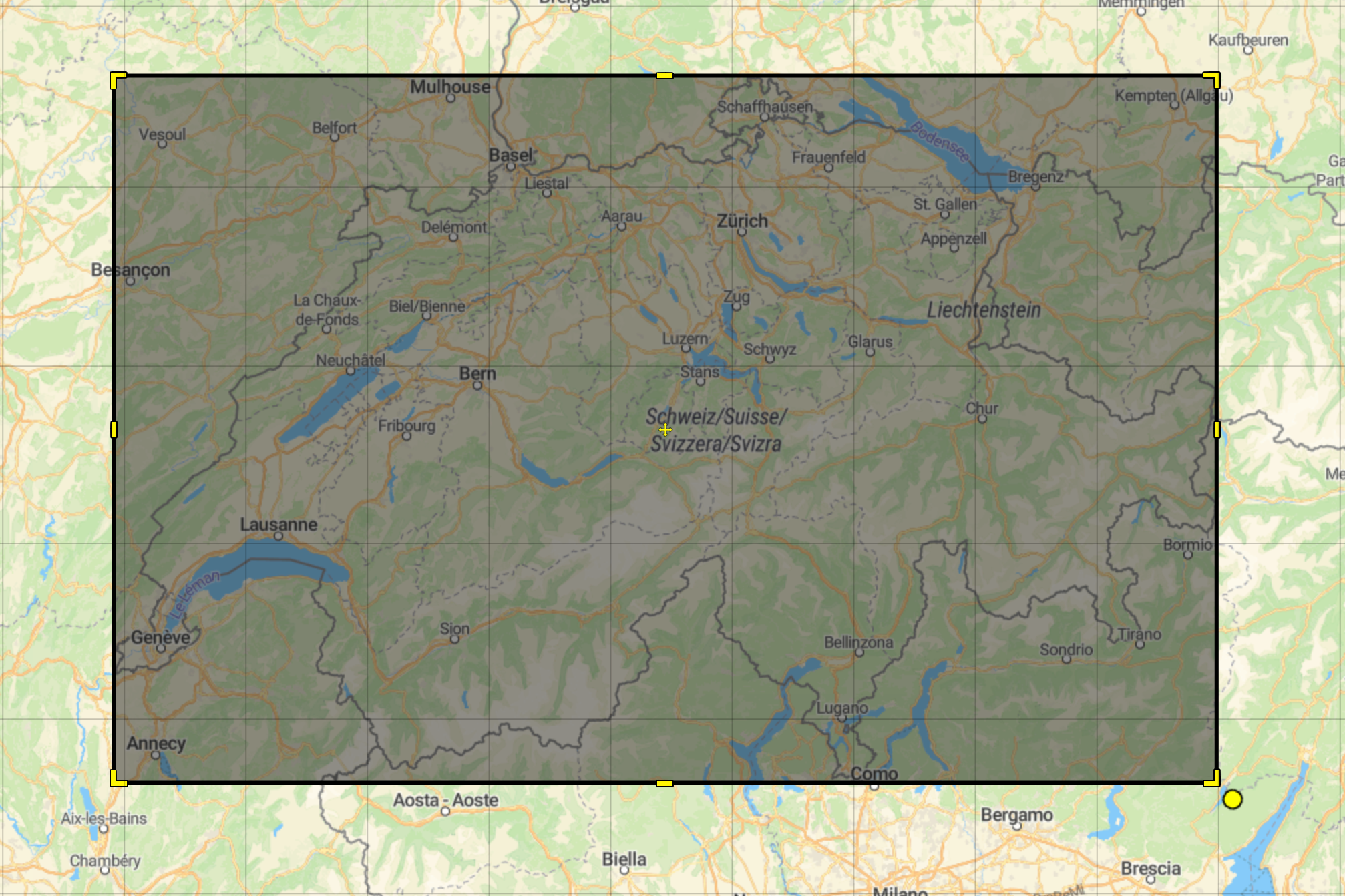
Cependant, cela ne suffira pas à lui seul — si un utilisateur dézoome pour voir le monde entier, le jeu de données pourrait encore être énorme.
Clustering
Ici, nous abordons le volume de données. Des millions de propriétés signifiaient des millions de points de données individuels. Envoyer tout cela vers le frontend était hors de question. Le clustering côté serveur était la solution évidente.
Au lieu d’afficher chaque propriété individuellement, nous allions regrouper les propriétés proches et afficher un seul marqueur avec un nombre représentant le total. Cela réduirait considérablement le nombre d’éléments que notre API backend devait envoyer, rendant la carte plus lisible et efficace.
En utilisant Elasticsearch, nous avons mis en place l’agrégation par Geotile grid pour gérer le clustering de nos géodonnées. Cela nous a permis d’agréger les propriétés en clusters basés sur leur emplacement géographique.
UX User Experience
Puis une autre question s’est posée : comment pourrions-nous mélanger de manière fluide à la fois des clusters et des marqueurs individuels ? L’agrégation par Geotile grid d’Elasticsearch ne nous permettait pas d’exposer à la fois des marqueurs et des clusters simultanément via notre API. Nous étions déterminés à offrir la meilleure expérience utilisateur possible, donc avoir des clusters d’un seul élément au lieu d’afficher le marqueur réel n’était pas une option (du moins pas à grande échelle)
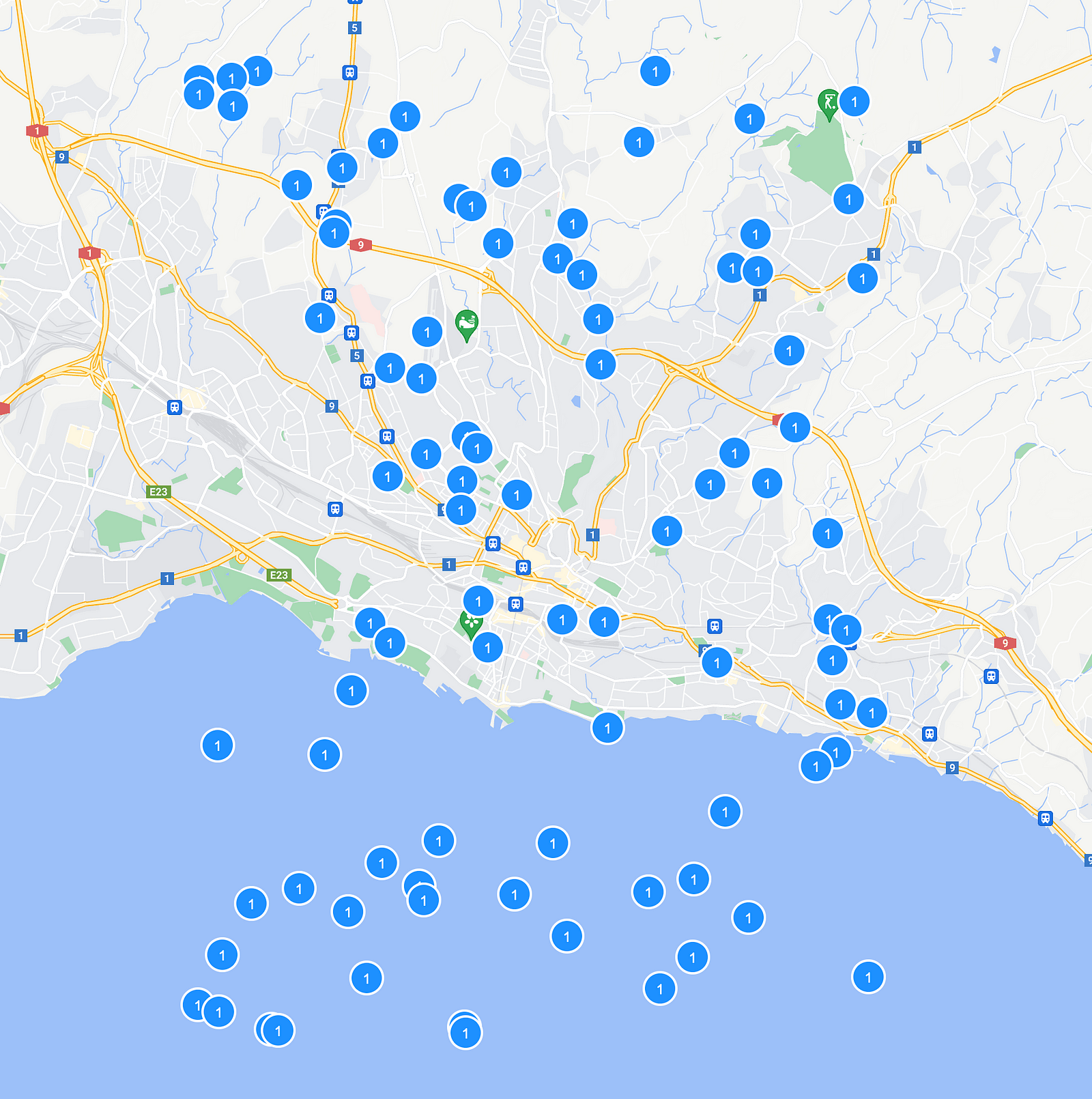
Ce qui peut résulter d’une stratégie de clustering côté serveur, c’est d’avoir des clusters ne contenant qu’un seul élément.
Après une bonne discussion autour d’un café, nous avons élaboré une stratégie pour combiner le clustering côté serveur et côté client.

Nous avons créé deux endpoints:
/clusterspour la navigation à un niveau élevé (niveaux de zoom 0-10) où les propriétés sont fortement regroupées. Cependant, ce endpoint peut encore renvoyer des clusters ne contenant qu’une seule propriété./markerspour une inspection plus approfondie (niveaux de zoom 11-30) où les propriétés individuelles peuvent être affichées.
À des niveaux de zoom plus élevés, nous n’afficherions que des clusters, car chaque tuile de la carte pourrait contenir des milliers d’éléments. Mais à mesure que les utilisateurs zoomaient davantage, le système passerait à l’affichage de marqueurs individuels, garantissant une expérience fluide et réactive.
Cette stratégie nous a permis d’afficher efficacement plus d’un million de propriétés sur une carte, sans compromettre les performances ni l’expérience utilisateur. C’est un équilibre parfait entre innovation et pragmatisme, et cela a prouvé qu’avec la bonne approche, même les défis les plus redoutables peuvent être surmontés.
Implémentation backend
Pour les passionnés de technologie au premier rang, ceci est pour vous. Plongeons dans la mise en œuvre technique de la façon dont nous avons réussi à cartographier plus d’un million de propriétés. Je vais vous expliquer les composants clés de notre configuration Elasticsearch.
Je ne montrerai qu’un sous-ensemble de notre requête pour mettre en évidence certaines parties spécifiques.
Configuration de l’index Elasticsearch
Tout d’abord, pour gérer les données géographiques, votre index Elasticsearch doit être configuré avec une propriété typée comme
geo_point. Ce type permet à Elasticsearch de gérer nativement les emplacements géographiques.PUT /realestate
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}Cette configuration nous permet de stocker les coordonnées de latitude et de longitude pour chaque propriété, ce qui est crucial pour les fonctionnalités de clustering et de marqueurs qui suivent..
Markers Endpoint
Dans les cas où l’utilisateur zoome de près, nous devons afficher des marqueurs individuels au lieu de clusters. Ce endpoint gère la récupération des propriétés spécifiques dans notre fameuse Bounding Box.
Voici une version de notre requête avec un sous-ensemble de bouding-box:
POST /realestate/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"pin.location": {
"top_left": {
"lat": 40.73,
"lon": -74.1
},
"bottom_right": {
"lat": 40.01,
"lon": -71.12
}
}
}
}
}
}
}La réponse fournit les coordonnées détaillées de chaque propriété :
[
{
"lat": -34.936909378343,
"lon": -54.9183369647971,
"id": "0000c086-fa6d-4e2a-a029-d5af313c7d3f"
},
{
"lat": 49.1631672,
"lon": -122.0157818,
"id": "000a2251-dca9-4763-8d69-a8a8c1f7036a"
},
{
"lat": 31.903325,
"lon": -95.3027039,
"id": "00116edc-95e0-4a35-8ca3-340344a16620"
}
// A millions times ...
]Ce endpoint nous permet de fournir des données détaillées pour les niveaux de zoom où les clusters ne sont plus nécessaires, garantissant une transition fluide entre les différentes vues de la carte.
Clusters Endpoint
Pour éviter de surcharger le frontend avec des millions de marqueurs individuels, nous avons décidé d’agréger les propriétés en clusters en fonction de leur emplacement géographique. Pour cela, nous avons utilisé l’agrégation
geotile_grid d’Elasticsearch. Cette agrégation divise la carte en tuiles, regroupant les propriétés à l’intérieur de chaque tuile.Voici une version simplifiée de notre requête :
POST /realestate/_search?size=0
{
"aggregations": {
"large-grid": {
"geotile_grid": {
"field": "location",
"precision": 8
}
}
}
}Le paramètre de précision détermine la granularité de la grille — une précision plus élevée signifie des tuiles plus petites. La réponse pourrait ressembler à ceci :
[
{
"key": "8/131/84",
"doc_count": 3
},
{
"key": "8/129/88",
"doc_count": 2
},
{
"key": "8/131/85",
"doc_count": 1
}
]Pour faciliter le placement précis des clusters sur le frontend, nous avons calculé le centre géographique, ou centroïde, de chaque cluster. De cette manière, le frontend peut afficher le marqueur du cluster à l’emplacement le plus représentatif dans la grille, sans avoir à le calculer côté client.
POST /realestate/_search?size=0
{
"aggregations": {
"large-grid": {
"geotile_grid": {
"field": "location",
"precision": 8
},
"aggs": {
"centroid": {
"geo_centroid": {
"field": "location"
}
}
}
}
}
}La réponse inclut désormais à la fois le nombre de clusters et les coordonnées du centroïde :
[
{
"key": "20/543807/370868",
"doc_count": 8,
"geo_centroid": {
"location": {
"lat": 46.51612099260092,
"lon": 6.701349942013621
}
}
},
{
"key": "20/545343/372639",
"doc_count": 4,
"geo_centroid": {
"location": {
"lat": 46.096099968999624,
"lon": 7.228809949010611
}
}
}
]Conclusion
En mettant en œuvre stratégiquement ces requêtes et points de terminaison Elasticsearch, et en combinant un mélange de clustering côté client et côté serveur, nous avons réussi à créer une interface de carte hautement efficace, capable d’afficher des millions de propriétés sans sacrifier les performances. Que ce soit pour le clustering à un niveau de zoom élevé ou pour l’affichage de marqueurs individuels de près, notre solution garantit une expérience fluide et réactive.

Success ! We make it 🎉
Sources
Arthur C. Codex (2024) Why Clustering your Google Map markers in the server side?
reintech.io/…/handling-large-datasets-...-marker-clustering
reintech.io/…/handling-large-datasets-...-marker-clustering
Elastic (2023) Comparing Geotile and Geohex in Kibana.
youtube.com/watch?v=ucI6OeYlu50
youtube.com/watch?v=ucI6OeYlu50
Mateusz Jasiński (2022) Clustering on maps with Elasticsearch.
medium.com/@mateusz-jasinski/clustering-on-maps
medium.com/@mateusz-jasinski/clustering-on-maps
Louis Z. (2021) Server-side Map Clustering.
louisz.medium.com/server-side-map-clustering
louisz.medium.com/server-side-map-clustering
Victor Barzana (2020) Why Clustering your Google Map markers in the server side?
viticoinf.medium.com/why-clustering-your-google-map-markers
viticoinf.medium.com/why-clustering-your-google-map-markers
Ion Bazan (Apr, 2021) Efficiently resolving composer.lock merge conflicts.
https://dev.to/ionbazan/efficiently-resolving-composer-lock-merge-conflicts-1peb
https://dev.to/ionbazan/efficiently-resolving-composer-lock-merge-conflicts-1peb
Mika Tuupola (2008) Introduction to Marker Clustering With Google Maps
appelsiini.net/2008/introduction-to-marker-clustering-with-google-maps
appelsiini.net/2008/introduction-to-marker-clustering-with-google-maps
Resources
ChatGPT, http://chat.openapi.com
Pour aider à la rédaction et à la traduction
Pour aider à la rédaction et à la traduction
Claude AI, https://claude.ai
Pour la génération du code pour expliquer les concepts
Pour la génération du code pour expliquer les concepts