How we create an Interactive Maps showcasing over a millions of items
Auteur(s) de l'article
I recently being challenged by one of our client, a real estate company. They wanted an interactive map showcasing all their worldwide properties. The catch ? They have over a million properties. And so, our journey began.
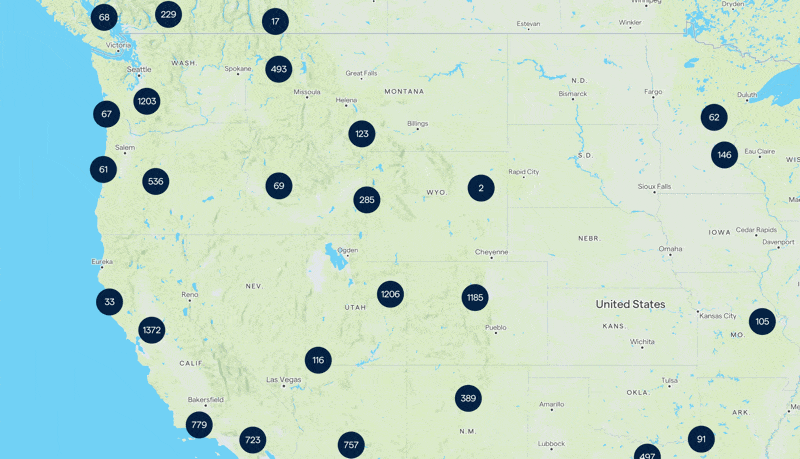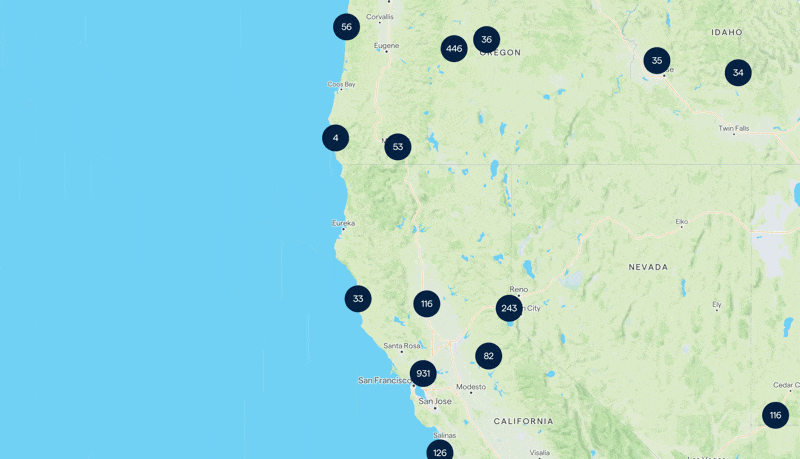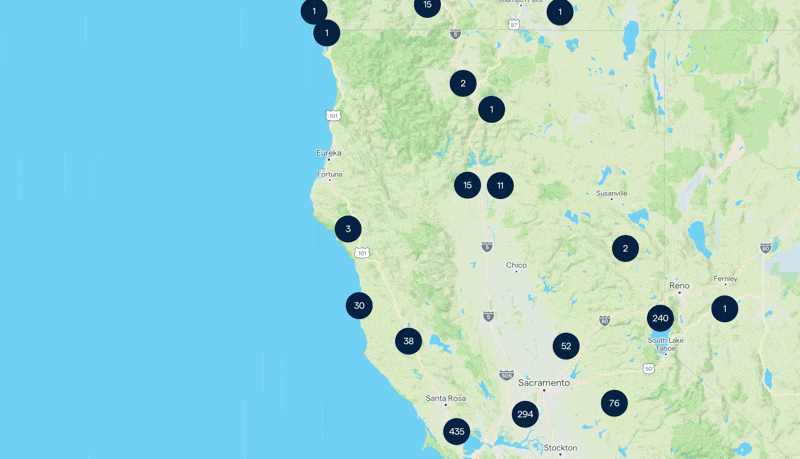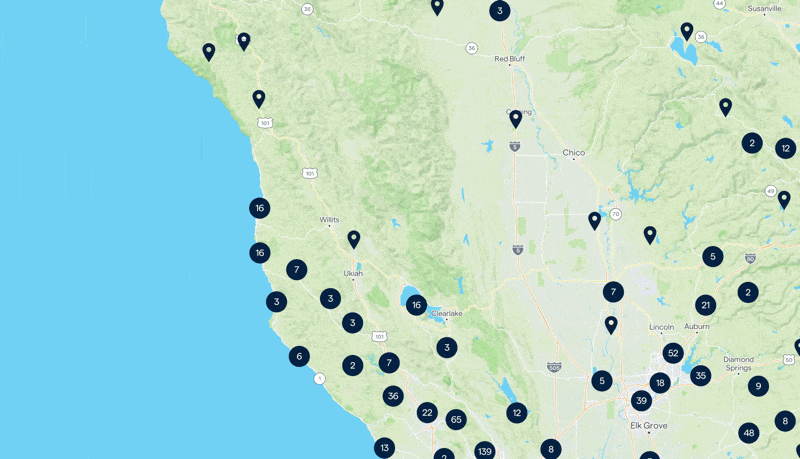
At first glance, it seemed straightforward. The real challenge wasn’t just displaying millions of properties but doing so in a way that was both fast and efficient. A map that sluggishly loads markers or crashes under the weight of data would be a disaster.
The scope
The initial requirements are quite simple:
- Display millions of properties worldwide.
- Show clusters of properties when many were located in close proximity, dynamically adjusting as users zoomed in or out.
- Must be blazing fast, regardless of the location or number of properties visible on the screen.
I felt this wasn’t going to be a simple case of pulling data from our Elasticsearch and rendering it on a map.
Imagine trying to display every single property as a marker . The result would be an indecipherable sea of dots, overwhelming both the map and the user.

Even with client-side clustering, the real challenge would be the size of our data. Just think about the weight of an API payload containing millions of markers — it would be a nightmare for data transfer and your mobile data plan’s worst enemy.
“ We had to find a solution that balanced performance, scalability and functionality. ”
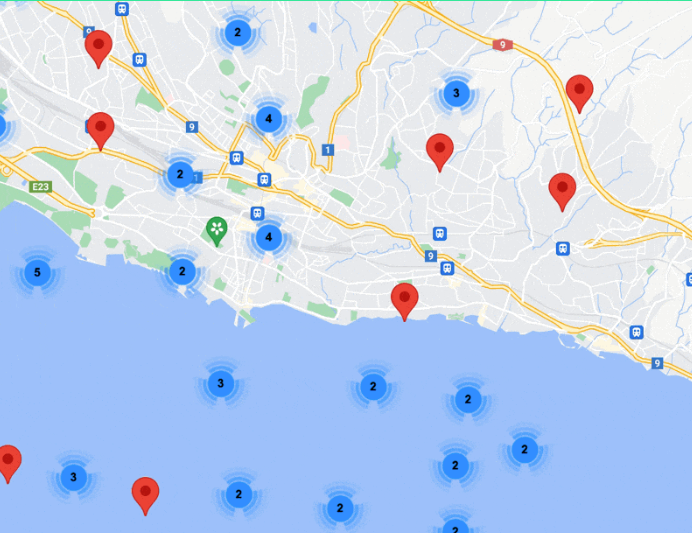
Brainstorming
We needed a solution that balanced performance, scalability, and feature. So, we started by breaking down the problem.
Bounding Box Filtering
To reduce the number of items requested from our index, we decided to enforce the frontend application to provide a bounding box. This bounding box would represent the visible portion of the map on the user’s screen, filtering out any properties outside this area.
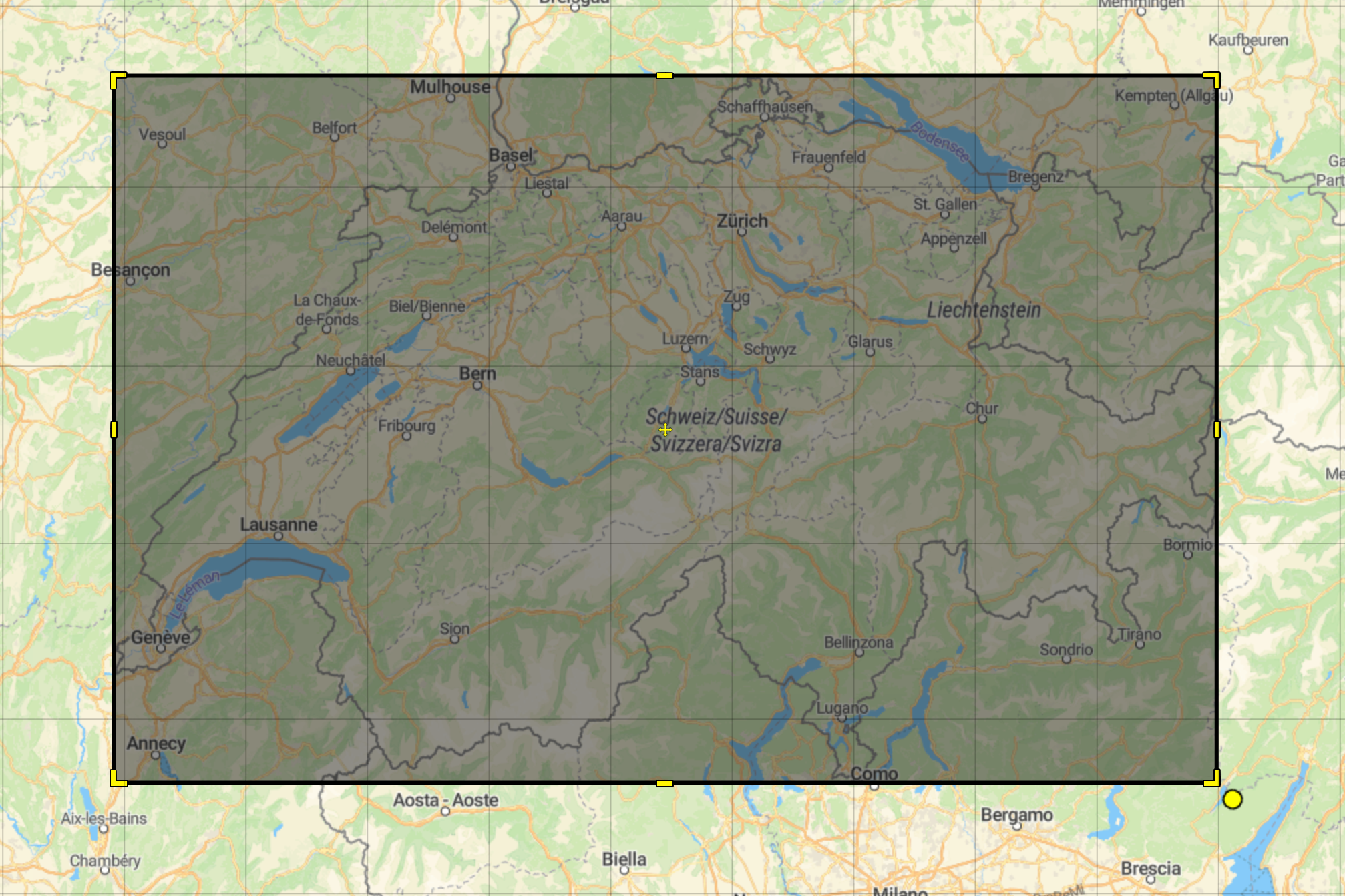
However, this alone will not be enough — if a user zoomed out to view the whole world, the dataset could still be massive.
Clustering
Here we tackle the volume of data. Millions of properties meant millions of individual data points. Sending all of these to the frontend was out of the question. Server-side Clustering was the obvious solution.
Instead of displaying every single property, we’d group nearby properties and show a single marker with a number representing the count. This would significantly reduce the number of elements our backend API needed to send, making the map more readable and efficient.
Using Elasticsearch, we implemented geotile grid aggregation to handle clustering over our geodata. This allowed us to aggregate properties into clusters based on their geographical location.
User Experience
Then another question pop-up: How could we mix both clusters and individual markers seamlessly ? Elasticsearch’s geotile grid aggregation wouldn’t let us expose both markers and clusters simultaneously through our API. We were committed to providing the best user experience possible, so having clusters of just one element instead of displaying the actual marker wasn’t an option (at lest not at large scale).
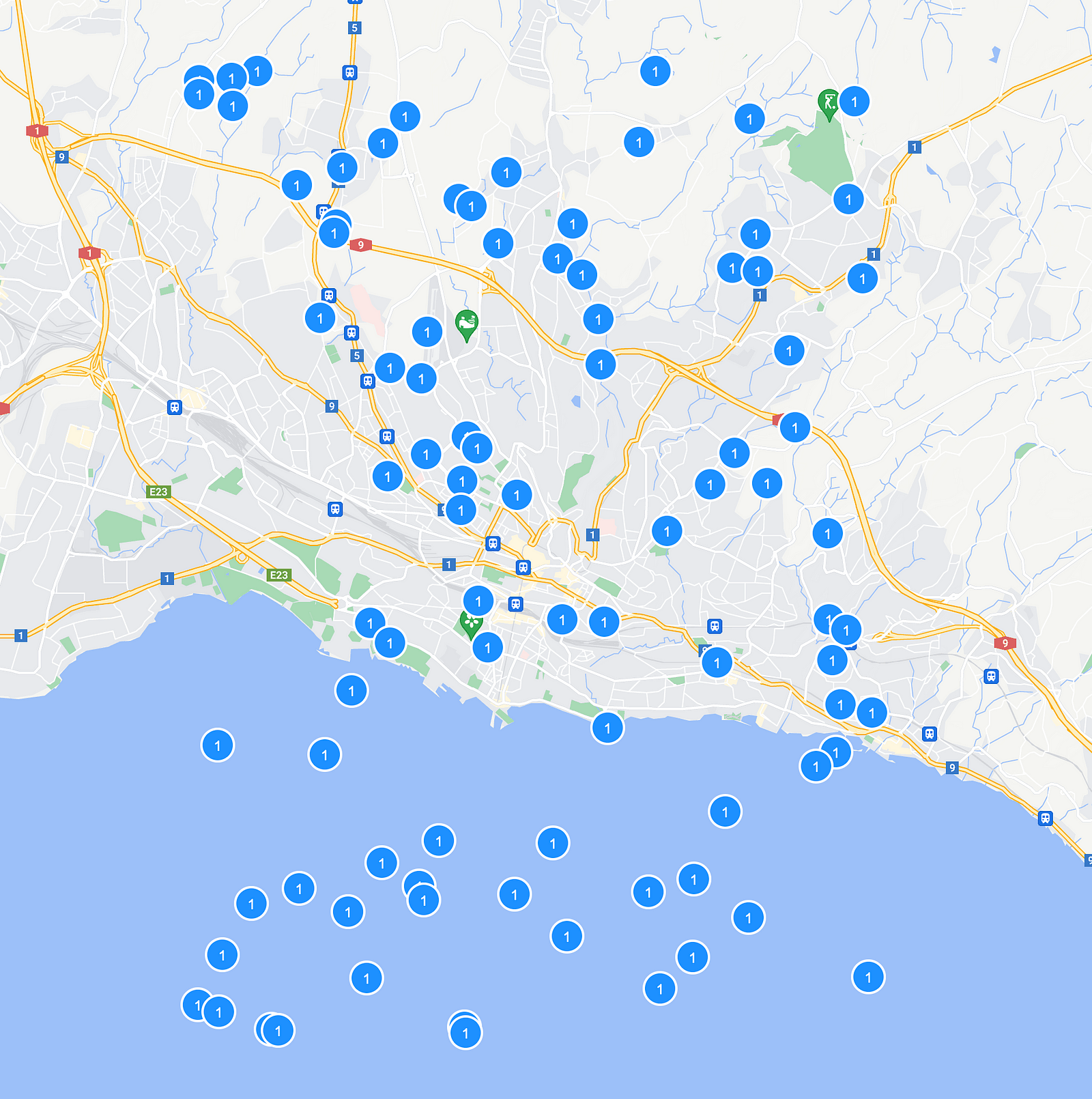
After a good discussion around a coffee, we devised a strategy to mix server-side and client-side clustering.

We created two endpoints:
/clustersfor higher-level navigation (zoom levels 0-10) where properties are heavily clustered. However, this endpoint may still return clusters containing only a single property./markersfor closer inspection (zoom levels 11–30) where individual properties can be displayed.
At higher zoom levels, we would only show clusters since every tile of the map could contain thousands of items. But as users zoomed in closer, the system would switch to displaying individual markers, ensuring a clean and responsive experience.
This strategy allowed us to efficiently display over a million properties on a map without compromising performance or user experience. It is a perfect balance between innovation and practicality, and it proved that with the right approach, even the most daunting challenges can be overcome.
Backend implementation
For the tech enthusiasts in the front row, this one’s for you. Let’s dive into the technical implementation of how we managed to map over a million properties. I’ll walk you through the key components of our Elasticsearch setup.
I will only show subset of our query to highlight specific parts of them.
Elasticsearch Index Setup
First things first, to handle geographic data, your Elasticsearch index needs to be set up with a property typed as
geo_point. This type allows Elasticsearch to natively handle geographic locations.PUT /realestate
{
"mappings": {
"properties": {
"location": {
"type": "geo_point"
}
}
}
}This mapping allows us to store latitude and longitude coordinates for each property, which is crucial for the clustering and marker functionalities that follow.
Markers Endpoint
For cases where the user zooms in closely, we needed to display individual markers instead of clusters. This endpoint handles the retrieval of specific properties within the visible area of the map.
Here’s a the bouding-box subset version of our query:
POST /realestate/_search
{
"query": {
"bool": {
"must": {
"match_all": {}
},
"filter": {
"geo_bounding_box": {
"pin.location": {
"top_left": {
"lat": 40.73,
"lon": -74.1
},
"bottom_right": {
"lat": 40.01,
"lon": -71.12
}
}
}
}
}
}
}The response provides detailed coordinates for each property:
[
{
"lat": -34.936909378343,
"lon": -54.9183369647971,
"id": "0000c086-fa6d-4e2a-a029-d5af313c7d3f"
},
{
"lat": 49.1631672,
"lon": -122.0157818,
"id": "000a2251-dca9-4763-8d69-a8a8c1f7036a"
},
{
"lat": 31.903325,
"lon": -95.3027039,
"id": "00116edc-95e0-4a35-8ca3-340344a16620"
}
// A millions times ...
]This endpoint allows us to serve detailed data for zoom levels where clusters are no longer necessary, ensuring a seamless transition between different map views.
Clusters Endpoint
To avoid overwhelming the frontend with millions of individual markers, we decided to aggregate properties into clusters based on their geographic location. For this, we used Elasticsearch’s
geotile_grid aggregation. This aggregation divides the map into tiles, grouping properties within each tile.Here’s a simplified version of our query:
POST /realestate/_search?size=0
{
"aggregations": {
"large-grid": {
"geotile_grid": {
"field": "location",
"precision": 8
}
}
}
}The
precision parameter determines the granularity of the grid—higher precision means smaller tiles. The response might look something like this:[
{
"key": "8/131/84",
"doc_count": 3
},
{
"key": "8/129/88",
"doc_count": 2
},
{
"key": "8/131/85",
"doc_count": 1
}
]To make it easier to place clusters accurately on the frontend, we computed the geographic center, or centroid, of each cluster. This way, the frontend can display the cluster marker at the most representative location within the grid without having to calculate it from the Client-side.
POST /realestate/_search?size=0
{
"aggregations": {
"large-grid": {
"geotile_grid": {
"field": "location",
"precision": 8
},
"aggs": {
"centroid": {
"geo_centroid": {
"field": "location"
}
}
}
}
}
}The response now includes both the cluster count and the centroid’s coordinates:
[
{
"key": "20/543807/370868",
"doc_count": 8,
"geo_centroid": {
"location": {
"lat": 46.51612099260092,
"lon": 6.701349942013621
}
}
},
{
"key": "20/545343/372639",
"doc_count": 4,
"geo_centroid": {
"location": {
"lat": 46.096099968999624,
"lon": 7.228809949010611
}
}
}
]Conclusion
By strategically implementing these Elasticsearch queries and endpoints, combining a mix of Client-Side and Server-Side clustering we were able to create a highly efficient map interface capable of displaying millions of properties without sacrificing performance. Whether it’s clustering at a high zoom level or displaying individual markers up close, our solution ensures a smooth and responsive experience.

Success ! We make it 🎉
Sources
Arthur C. Codex (2024) Why Clustering your Google Map markers in the server side?
reintech.io/…/handling-large-datasets-...-marker-clustering
reintech.io/…/handling-large-datasets-...-marker-clustering
Elastic (2023) Comparing Geotile and Geohex in Kibana.
youtube.com/watch?v=ucI6OeYlu50
youtube.com/watch?v=ucI6OeYlu50
Mateusz Jasiński (2022) Clustering on maps with Elasticsearch.
medium.com/@mateusz-jasinski/clustering-on-maps
medium.com/@mateusz-jasinski/clustering-on-maps
Louis Z. (2021) Server-side Map Clustering.
louisz.medium.com/server-side-map-clustering
louisz.medium.com/server-side-map-clustering
Victor Barzana (2020) Why Clustering your Google Map markers in the server side?
viticoinf.medium.com/why-clustering-your-google-map-markers
viticoinf.medium.com/why-clustering-your-google-map-markers
Ion Bazan (Apr, 2021) Efficiently resolving composer.lock merge conflicts.
https://dev.to/ionbazan/efficiently-resolving-composer-lock-merge-conflicts-1peb
https://dev.to/ionbazan/efficiently-resolving-composer-lock-merge-conflicts-1peb
Mika Tuupola (2008) Introduction to Marker Clustering With Google Maps
appelsiini.net/2008/introduction-to-marker-clustering-with-google-maps
appelsiini.net/2008/introduction-to-marker-clustering-with-google-maps
Resources
ChatGPT, http://chat.openapi.com
Assisting with writing and correcting my faulty English.
Assisting with writing and correcting my faulty English.
Claude AI, https://claude.ai
Generating map example code to illustrate concepts.
Generating map example code to illustrate concepts.
All images copyright of their respective owners.
Big thanks to @Antistatique for the review.
Big thanks to @Antistatique for the review.